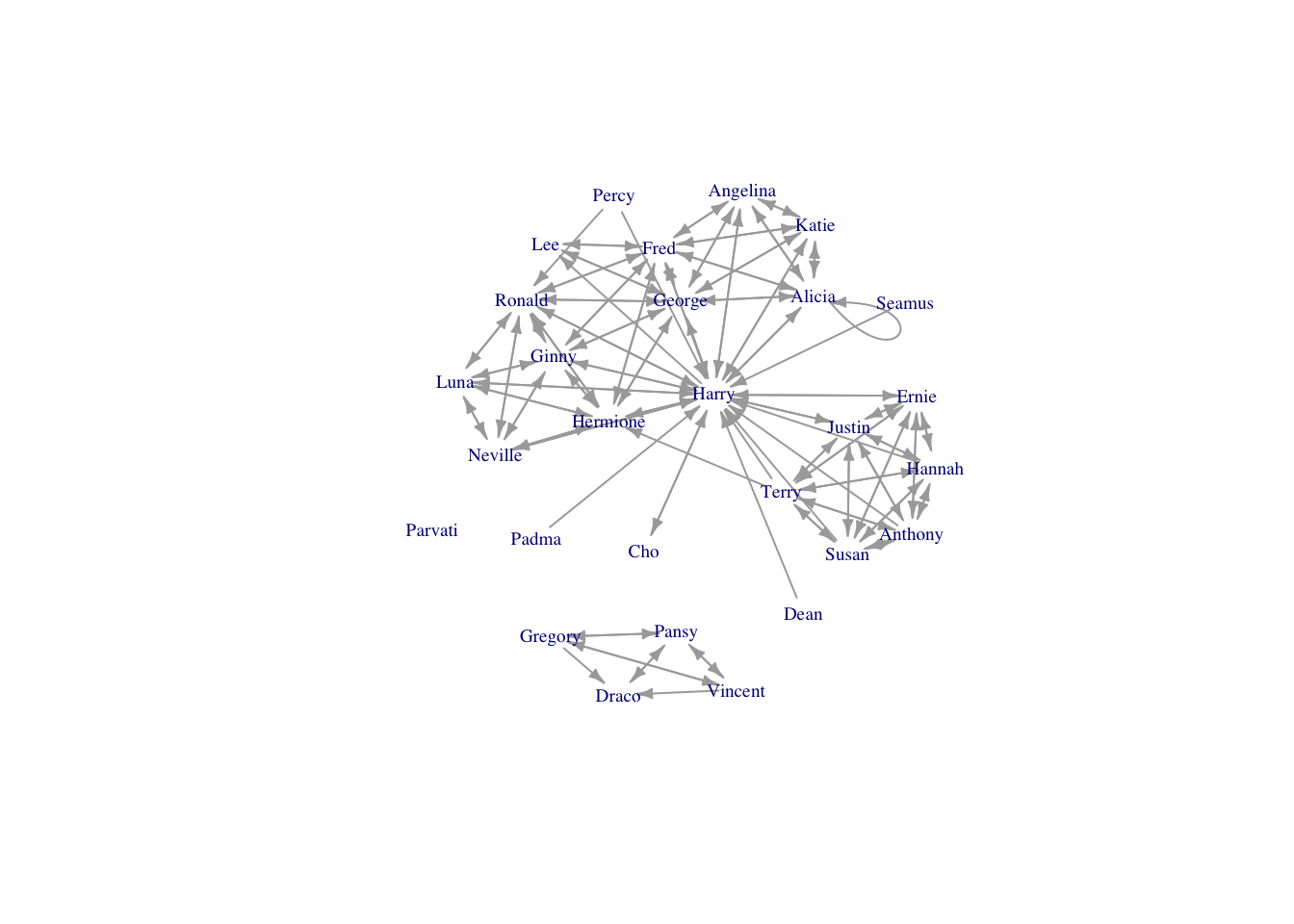
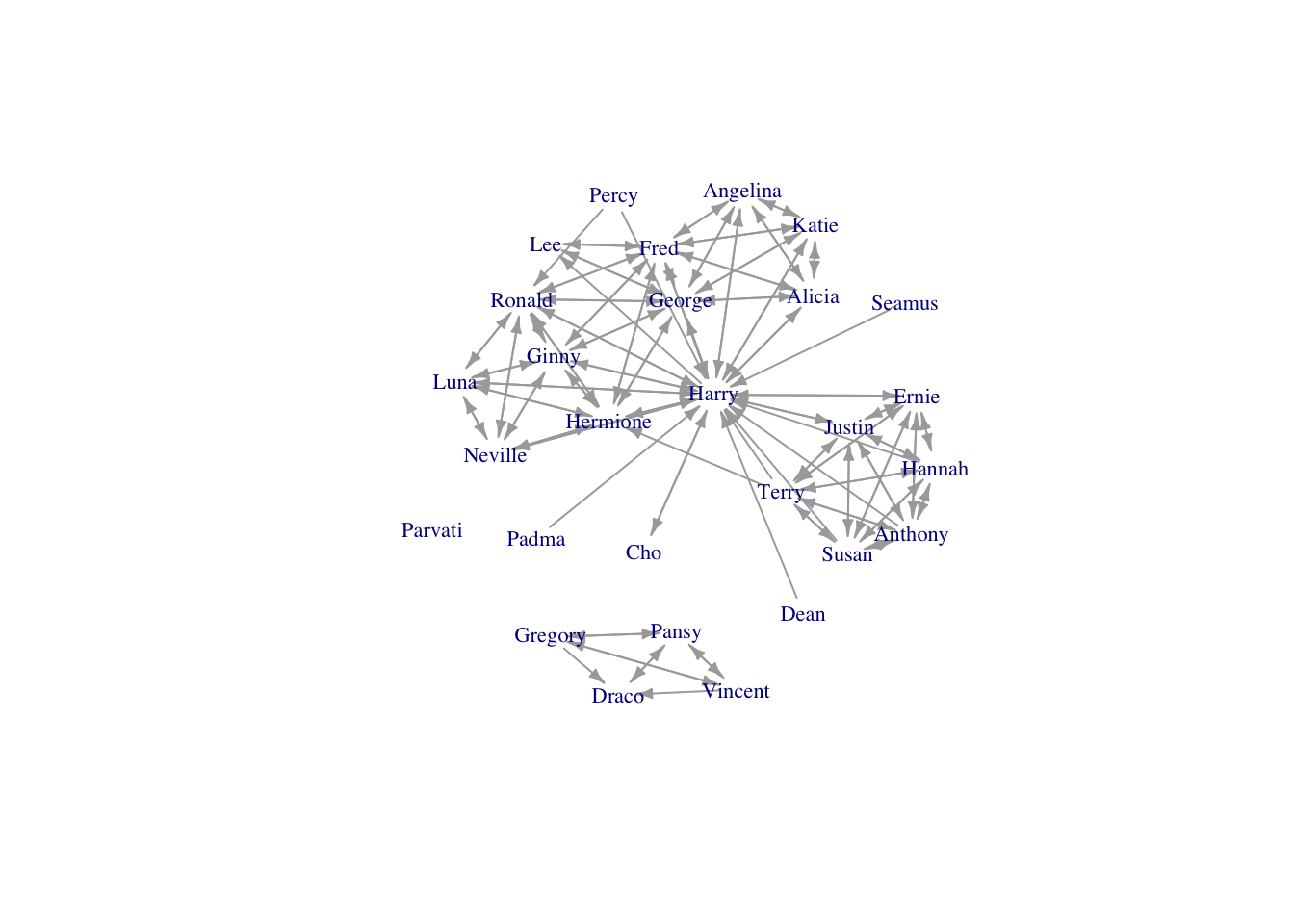
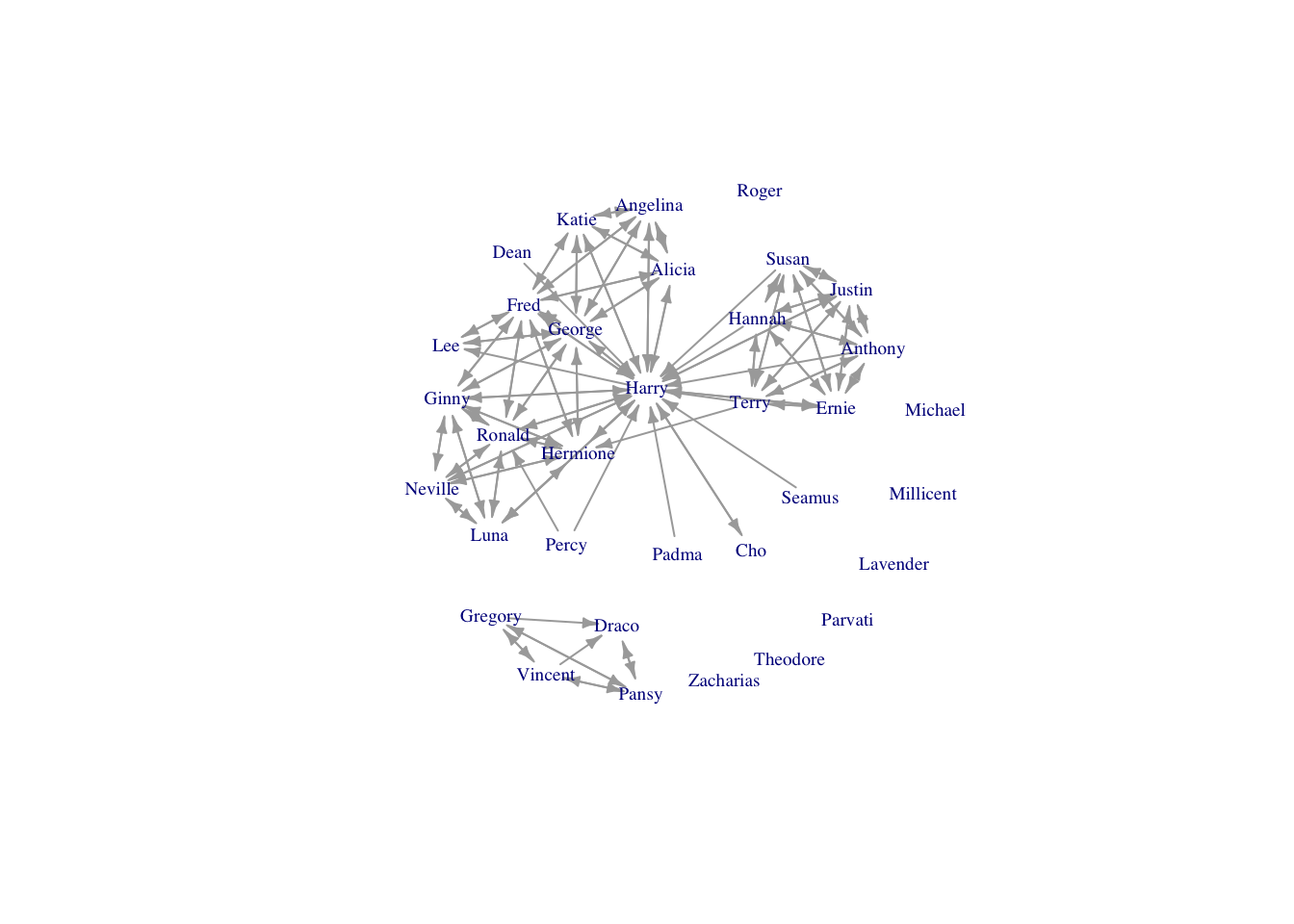
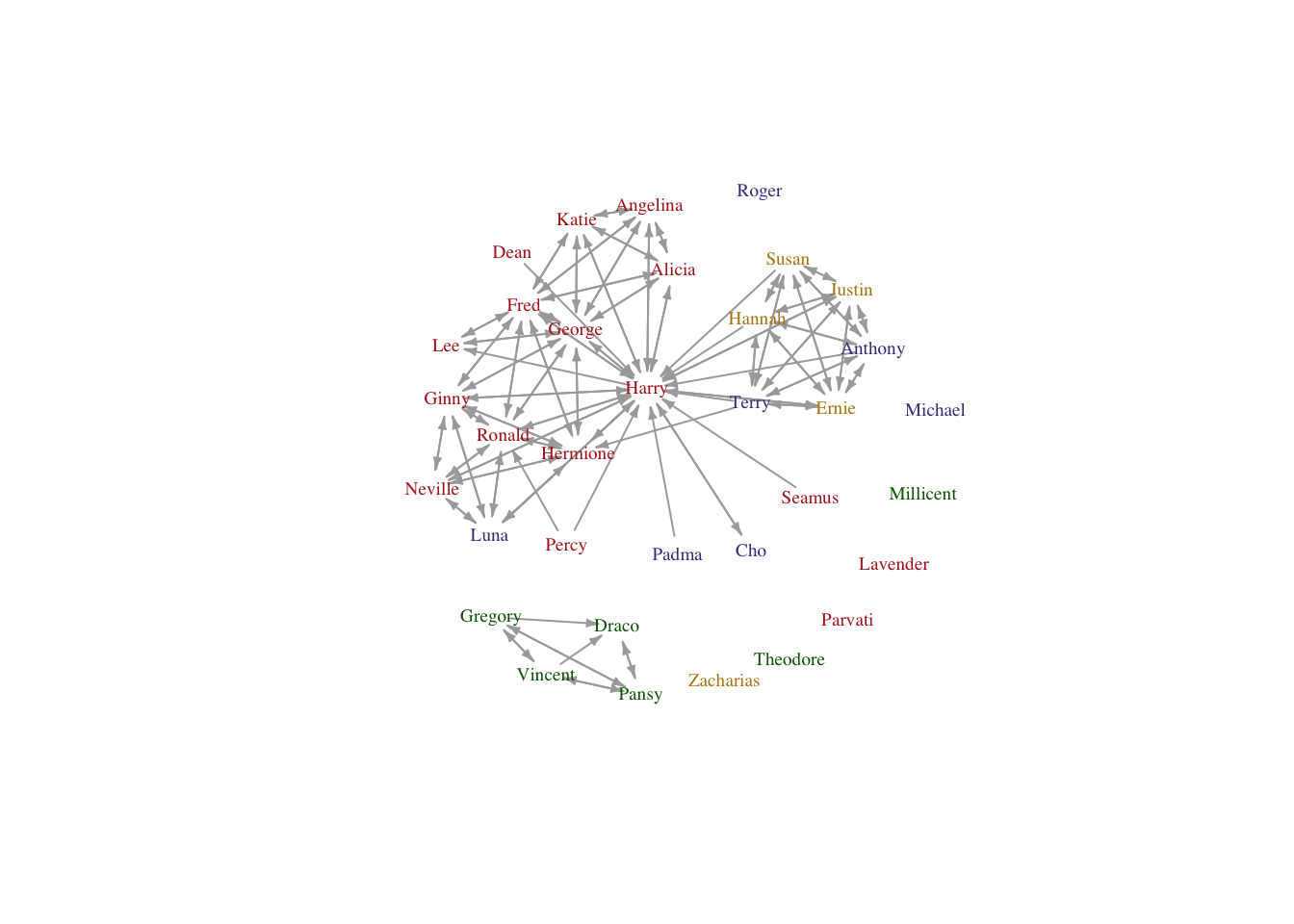
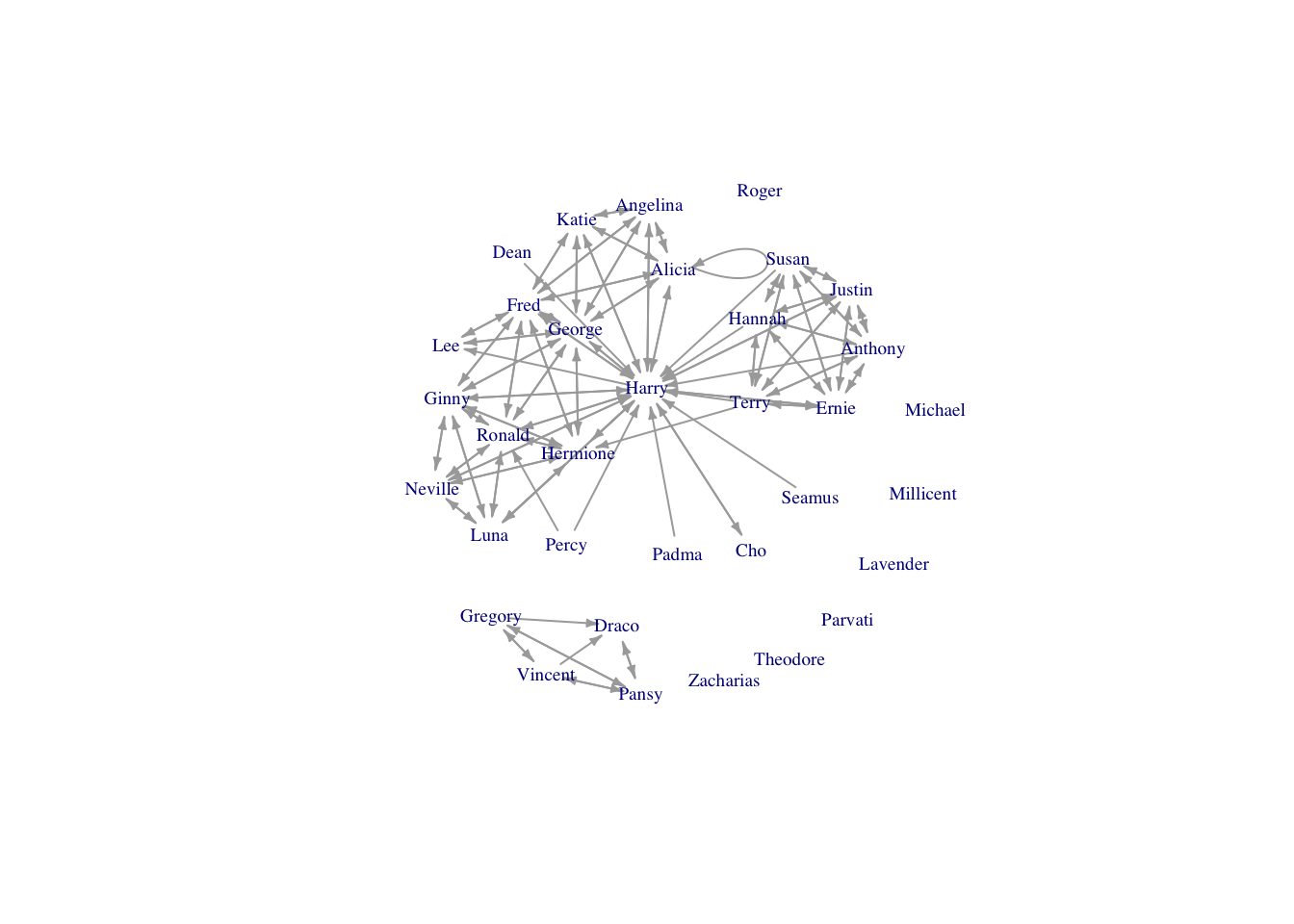
require(igraph)
library(knitr)
p1 <- c("Harry", "Harry", "Hermione")
p2 <- c("Hermione", "Ron", "Ron")
values <- c(5,6,5)
schoolmodel <- data.frame(p1, p2, values)
colnames(schoolmodel) <- c("Ego", "Alter", "Value")
knitr::kable(schoolmodel)| Ego | Alter | Value |
|---|---|---|
| Harry | Hermione | 5 |
| Harry | Ron | 6 |
| Hermione | Ron | 5 |